
Pri práci s Google Analyticsom, Tag Managerom prípadne Data Studiom ste sa určite stretli so slovom regex. Pokiaľ sa chcete dozvedieť, čo tento výraz znamená, ako s ním pracovať a aké sú príklady jeho využitia, čítajte ďalej ;).
Regulárne výrazy, v skratke regex, sú šikovní pomocníci, ktorí nám značne uľahčujú prácu s textom. Najčastejšie ich používame pri filtrovaní, vyhľadávaní, vytváraní cieľov a segmentov.
Regex je špeciálny textový reťazec, ktorý hľadá požadovanú zhodu v texte. V našom prípade ho vieme využiť pri hľadaní zhody v url, názvoch udalostí, kľúčových slovách, zdrojoch návštevnosti…
Pretože má regex široké použitie (validácia dát, zhromažďovanie dát, web scraping), existuje viacero syntaxí. Google Analytics a Google Tag Manager používajú zjednodušenú verziu, ktorá sa mierne líši od syntaxi v Google Data Studiu.
Aby sme lepšie pochopili, o aké výrazy ide, nižšie popíšeme jednotlivé znaky, prezradíme ich význam a využitie v praxi.
Zvislá čiara (Pipe) (|)
Zvislá čiara je najpoužívanejším znakom, ktorý budete pri práci s Analyticsom potrebovať. Veľa regulárnych výrazov sa dá nahradiť už predvolenými možnosťami, ktoré vám Analytics ponúka, avšak zvislá čiara je stále potrebná.
Tento znak znamená jednoduché „alebo”.
Pokiaľ chceme vyfiltrovať pri zdrojoch návštevnosti dáta z Facebooku alebo Googlu, napíšeme jednoducho facebook|google. Analytics vyberie buď jeden, alebo druhý zdroj, prípadne obidva.

Tabuľkový filter v prehľade Zdroj / médium
Bodka (Dot) (.)
Bodka nahrádza akýkoľvek znak, namiesto ktorého ju použijete. Je to tzv. divoká karta.
Ak použijeme regex v slove .oma, zhodu budete mať v slovách doma, toma, koma, poma, atď. Slovo oma však regex nezoberie (musí tam byť miesto bodky nejaký znak).
Najlepšie využijeme potenciál bodky s ďalšími regulárnymi výrazmi.
Hviezdička (Asterisk) (*)
Ak chceme nájsť zhodu v žiadnom alebo viacerých položkách, použijeme hviezdičku.
Ako príklad uvediem moje meno Marianna. Niekto ho píše s jedným n, iný s dvomi n. Preto ho môžeme napísať takto: mariann*a. Zhoda bude pri mariana, marianna, mariannna, atď.
Bodka-hviezdička (Dot – Asterisk) (.*)
V prípade, že chceme nájsť zhodu vo všetkom, využijeme .*. Bodka s hviezdičkou je v regexe najsilnejšou kombináciou, ale treba si zvážiť, kde tento výraz použiť.
Pokiaľ potrebujeme vytvoriť filter v Analyticse, ktorý zabezpečí pripnutie názvu hostiteľa ku URI, bodka s hviezdičkou nám značne uľahčia prácu.
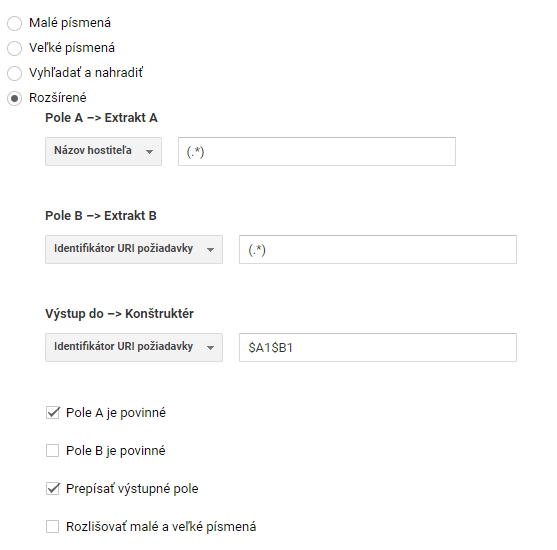
Použitie (.*) vo filtri
Zátvorka v tomto prípade slúži na definovanie skupiny (premennej). Vďaka tomuto filtru sa v reportoch v Analyticse zobrazí celá URL adresa.
Predstavte si, že máme na webovej stránke viacero kategórií. URL sú nasledovné:
- /produkty/damske/nohavice/
- /produkty/panske/nohavice/
- /produkty/detske/nohavice/
Pokiaľ chceme pozrieť dáta špecificky pre všetky nohavice, ale nezáleží nám na tom, či sú dámske, pánske alebo detské, vytvoríme nasledovný filter:
/produkty/.*/nohavice/
Takto budeme v reportoch vidieť všetky 3 kategórie. Pokiaľ však máme aj adresu /produkty/zlavy/nohavice/, regex nájde zhodu aj v nej.
Keďže .* nájde zhodu vo všetkom, doba sprocesovania je dlhšia.
Plusko (Plus sign) (+)
Plusko hľadá zhodu v jeden až viackrát podľa predchádzajúceho znaku.
Ak máme slovo ahoj+, zhoda bude aj v slovách ahoj, ahojj, ahojjj, ahojjjjjj, atď.
Otáznik (Question mark) (?)
Otáznik znamená, že predchádzajúci znak nie je povinný. Čiže sa môže, ale aj nemusí nachádzať v danom slove.
Ako príklad môžeme uviesť slovo súčasnosť. Často sa stáva, že ľudia nevedia dané slovo správne napísať. Pokiaľ použijeme regex sucast?nost, zhoda bude v slove sucasnost aj sucastnost.
Tento znak je veľmi užitočný pri rôznych preklepoch.
Okrúhle zátvorky (Parentheses) (())
Určite si pamätáte, ako zátvorky menia v matematike prednosť v počítaní. Napríklad:
- 3 × 5 + 10 = 25
- 3 × (5 + 10) = 45
Podobný princíp je aj pri zátvorkách v regexe. Zátvorkami zoskupíme výrazy a až následne spravíme kalkuláciu.
Zoberme si príklad s filtrovaním nohavíc, ktorý sme si uviedli pri bodke s hviezdičkou:
- /produkty/damske/nohavice/
- /produkty/panske/nohavice/
- /produkty/detske/nohavice/
Pokiaľ chceme dosiahnuť 100 % zhodu, musíme regex napísať takto:
^/produkty/(panske|damske|detske)/nohavice/$
V preklade to znamená – nájdi zhodu vo pre všetky URI, ktoré sa začínajú na /produkty a končia na nohavice/. Zároveň musí stredná cesta obsahovať slovo damske alebo panske alebo detske.
Hranaté zátvorky (Square brackets) ([])
Hranaté zátvorky používame vtedy, keď potrebujeme vytvoriť jednoduchý zoznam.
Napr.regex v[oae]da nájde zhodu v slove voda, vada, veda.
Plný potenciál hranatých zátvoriek môžeme využiť použitím pomlčky.
Pomlčka (Dash) (–)
Pre vytvorenie pokročilejšieho zoznamu používame pomlčku. Zlatým pravidlom je použitie pomlčky spolu s hranatými zátvorkami. Najčastejšie môžeme použiť tieto zoznamy:
- [a-z] nájde zhodu vo všetkých malých písmenách,
- [A-Z] nájde zhodu vo všetkých veľkých písmenách,
- [0-9] nájde zhodu vo všetkých číslach,
- [a-zA-Z0-9] nájde zhodu vo všetkých malých, veľkých písmenách a číslach.
Príklad:
Zo stránky si používatelia sťahujú pdf katalógy. V značkách Udalostí (Event Label) si chceme vyfiltrovať iba tieto:
- rok2017.pdf
- rok2018.pdf
- rok2019.pdf
Existuje viacero spôsobov, ako by mohol regex vyzerať:
- ^rok201[7-9]\.pdf$
- ^rok201[7|8|9]\.pdf$
- (rok2017\.pdf)|(rok2018\.pdf)|(rok2019\.pdf)
Ako vidíte, najlepšou cestou je zoznam, pretože je prehľadnejší, rýchlejšie ho vieme upraviť a je menšia pravdepodobnosť, že sa niekde pomýlime.
Strieška (Caret) (^)
Znak striešky sme použili v predchádzajúcich príkladoch už viackrát. Tento znak jednoducho znamená Začína sa na…. V Analyticse ho častokrát vieme nahradiť priamo výberom z možností.
Ako príklad si uvedieme ^topanky, kde tento výraz bude mať zhodu v nasledujúcich slovách: topanky, topankach, topanky na zimu. Do zhody však nepatria zimne topanky, letne topanky, detske topanky, atď.
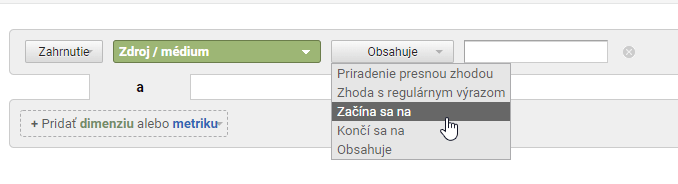
Dolár (Dolar sign) ($)
Znak dolára má podobné uplatnenie, ako strieška. Rozdiel je len v tom, že označuje Končí sa na…. Takisto ho vieme vo väčšine prípadov nahradiť výberom z ponúkaných možností.
Ostaneme pri príklade topánok. Regex topanky$ nájde zhodu v slovách: topanky, zimne topanky, letne topanky, ale nie v slovnom spojení topanky zima, topanky leto, topankach, atď.
Opačná lomka (Backslash) (\)
Opačná lomka je veľmi užitočný znak a nemali by sme naň zabúdať. Používa sa vtedy, keď chceme „premeniť” regexový znak na normálny znak, ktorý nemá iný význam.
Opäť si uvedieme príklad filtrovania IPčky. Pokiaľ chceme odfiltrovať iba túto jednu IP adresu, musíme vynechať bodku, ktorá oddeľuje jednotlivé čísla od seba: 67\.172\.171\.105 – v takomto prípade nájde regex zhodu iba v danej IP 67.172.171.105.
Ako už vieme, bodka znamená akýkoľvek jeden znak. Pri filtrovaní IP adresy však potrebujeme len obyčajnú bodku.
Ďalším príkladom je parameter, ktorý je v URL označený otáznikom.
Ak chceme napríklad vyfiltrovať túto URI /globaldeals?_trkparms=%26clkid ,musí regex vyzerať takto: /globaldeals\?_trkparms=%26clkid.
Zložené zátvorky (Curly brackets) ({})
Poďme na posledný výraz – zložené zátvorky. Aby sme si ich vysvetlili, uvedieme rovno príklad:
- {1,2} – znamená, aby sa posledná položka zopakovala minimálne 1-krát, ale nie viac ako 2-krát,
- {2} – znamená, aby sa posledná položka zopakovala 2-krát.
Prvý príklad môžeme použiť pri vytváraní IP filtrov. Pokiaľ chceme nájsť zhodu v tomto rozpätí IP adries 77.120.120.0 až do 77.120.120.99, musíme regex napísať takto: ^77\.120\.120\.[0–9]{1,2}$.
Druhý príklad si môžeme ukázať na PSČ. Tento príklad nie je vhodný pre Google Analytics, pretože PSČ je osobný údaj (v konečnom dôsledku aj celá IP adresa), ale pre pochopenie to bude stačiť.
Zoberme si PSČ, ktoré začína 811. Pokiaľ chceme nájsť zhodu vo všetkých číslach, napíšeme regex nasledovne: 811[0–9]{2}, čiže zhoda bude vo všetkých číslach, ktoré začínajú na 811xx a zvyšné 2 čísla sú ľubovoľné od 0 po 9.
Lazy matching a greedy matching
Na záver spomenieme ešte dva výrazy, s ktorými sa pri regexe môžete stretnúť:
- lazy matching – tzv. lenivá zhoda – vráti čo najkratšiu možnú zhodu (nájde prvú zhodu a už nepokračuje v hľadaní ďalej),
- greedy matching – tzv. nenásytná zhoda – vráti čo najdlhšiu možnú zhodu (pokračuje dovtedy, kým má nejakú zhodu).
Napríklad, chceme nájsť zhodu pre nasledujúci výraz
- <.+?> – lazy matching – Hello World– čiže regex nájde prvú zhodu div parametre v zátvorkách a ďalej už nehľadá,
- <.+> – greedy matching – Hello World– v tomto prípade nájde regex úplne všetko, čo sa nachádza medzi zátvorkami.
Zhrnutie:
V tabuľkách nižšie nájdete prehľadne zobrazené jednotlivé znaky, ich význam, ako aj príklady použitia.
| | | Zhoda s jednou alebo druhou položkou |
| . | Zhoda s ľubovoľným jedným znakom |
| * | Zhoda so žiadnou alebo viacerými predchádzajúcimi položkami |
| + | Zhoda s jednou alebo viacerými predchádzajúcimi položkami |
| ? | Zhoda so žiadnou alebo jednou predchádzajúcou položkou |
| () | Zapamätanie obsahu zátvoriek ako položky |
| [] | Zhoda s jednou položkou v tomto zozname |
| {} | Zopakovanie poslednej položky od X po Y krát |
| – | Vytvorenie rozsahu v zozname |
| ^ | Položka sa začína s |
| $ | Položka sa končí s |
| \ | Vynechanie ľubovoľného z vyššie uvedených výrazov |
| | | cpc|ppc|cpm | cpc, ppc, cpm |
| . | .oma | toma, doma, koma, poma,…. |
| * | mariann*a | mariana, marianna, mariannna, …. |
| + | ahoj+ | ahoj, ahojj, ahojjj, …. |
| ? | sucast?nost | sucasnost, sucastnost |
| () | ^/produkty/(panske|damske|detske)/nohavice/$ | /produkty/panske/nohavice/
/produkty/damske/nohavice/ /produkty/detske/nohavice/ |
| [] | v[oae]da | voda, vada, veda |
| {} | ^77\.120\.120\.[0–9]{1,2}$ | 77.120.120.0 až do 77.120.120.99 |
| – | rok 201[7-9] | rok 2017, rok 2018, rok 2019 |
| ^ | ^topanky | topanky, topankach, topanky na zimu, ale nie zimne topanky |
| $ | topanky$ | topanky, zimne topanky, letne topanky, ale nie topanky zima |
| \ | 67\.172\.171\.105 | 67.172.171.105 |
Pokiaľ si chcete overiť, či máte regex napísaný správne, odporúčam stránku: https://regex101.com/. Keď plánujete regex používať na pravidelnej báze, určite vám príde vhod kurz, kde si ho môžete precvičiť.
Dúfam, že vám môj článok pomôže a uľahčí prácu so základnými regulárnymi výrazmi. Teším sa na vaše otázky a komentáre ;).